Introduction to web scraping
Motivation: Great British Bake Off
Goal and required steps
Goal: Explore the different baking challenges across all the different series. Which challenges appear most frequently? Which challenges appear earliest in the series?
Scrape episode information from each series
Combine and clean
Summarize the data, do statistics!
Scraping the data
library (rvest)library (tidyverse)<- read_html ("https://en.wikipedia.org/wiki/The_Great_British_Bake_Off_series_15" )
{html_document}
<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu-pinned-disabled vector-feature-limited-width-clientpref-1 vector-feature-limited-width-content-enabled vector-feature-custom-font-size-clientpref-1 vector-feature-appearance-pinned-clientpref-1 vector-feature-night-mode-enabled skin-theme-clientpref-day vector-sticky-header-enabled vector-toc-available" lang="en" dir="ltr">
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body class="skin--responsive skin-vector skin-vector-search-vue mediawik ...
HTML basics
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id='first'>A heading</h1>
<p>Some text & <b>some bold text.</b></p>
<img src='bakeoff_0.jpg' width='300' height='200'>
</body>
</html>
HTML basics
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id='first'>A heading</h1>
<p>Some text & <b>some bold text.</b></p>
<img src='bakeoff_0.jpg' width='300' height='200'>
</body>
</html>
A heading
Some text & some bold text.
Some HTML elements
<html>: start of the HTML page<head>: header information (metadata about the page)<body>: everything that is on the page<h1> to <h6>: headings<p>: paragraphs<b>: bold<table>: table
Finding the right selectors
(Demo)
Finding the right selectors
Open the web page in your browser (I find that Firefox or Chrome tend to work best)
Right-click on the element you want, and click “Inspect”
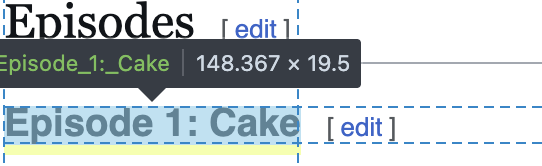
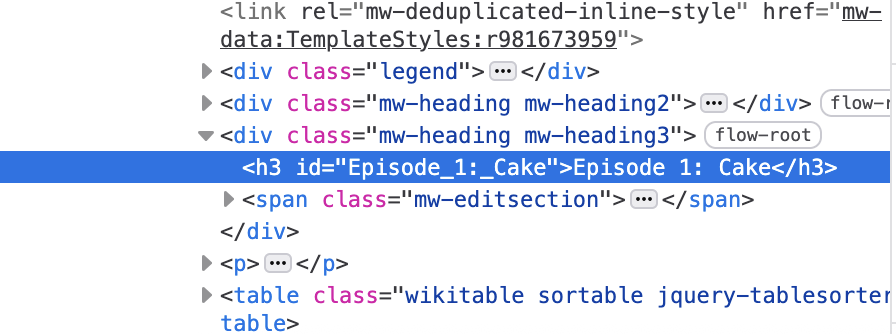
Finding the right selector
|> html_elements ("h3" )
{xml_nodeset (12)}
[1] <h3 id="Episode_1:_Cake">Episode 1: Cake</h3>\n
[2] <h3 id="Episode_2:_Biscuits">Episode 2: Biscuits</h3>\n
[3] <h3 id="Episode_3:_Bread">Episode 3: Bread</h3>\n
[4] <h3 id="Episode_4:_Caramel">Episode 4: Caramel</h3>\n
[5] <h3 id="Episode_5:_Pastry">Episode 5: Pastry</h3>\n
[6] <h3 id="Episode_6:_Autumn">Episode 6: Autumn</h3>\n
[7] <h3 id="Episode_7:_Desserts">Episode 7: Desserts</h3>\n
[8] <h3 id="Episode_8:_The_'70s_(Quarterfinals)">\n<span id=" ...
[9] <h3 id="Episode_9:_Patisserie_(Semifinal)">\n<span id="Ep ...
[10] <h3 id="Episode_10:_Final">Episode 10: Final</h3>\n
[11] <h3 id="The_Great_Christmas_Bake_Off"><i>The Great Christ ...
[12] <h3 id="The_Great_New_Year_Bake_Off"><i>The Great New Yea ...
Finding the right selector
|> html_elements ("h3[id^='Episode']" )
{xml_nodeset (10)}
[1] <h3 id="Episode_1:_Cake">Episode 1: Cake</h3>\n
[2] <h3 id="Episode_2:_Biscuits">Episode 2: Biscuits</h3>\n
[3] <h3 id="Episode_3:_Bread">Episode 3: Bread</h3>\n
[4] <h3 id="Episode_4:_Caramel">Episode 4: Caramel</h3>\n
[5] <h3 id="Episode_5:_Pastry">Episode 5: Pastry</h3>\n
[6] <h3 id="Episode_6:_Autumn">Episode 6: Autumn</h3>\n
[7] <h3 id="Episode_7:_Desserts">Episode 7: Desserts</h3>\n
[8] <h3 id="Episode_8:_The_'70s_(Quarterfinals)">\n<span id="Episode_8:_The_ ...
[9] <h3 id="Episode_9:_Patisserie_(Semifinal)">\n<span id="Episode_9:_Patiss ...
[10] <h3 id="Episode_10:_Final">Episode 10: Final</h3>\n
Class activity
Work independently or with a neighbor on the class activity
At the end of class, submit your work as an HTML file on Canvas (one per group, list all your names)