Intro to Iteration
Class activity
https://sta279-f25.github.io/class_activities/ca_11.html
- Work with a neighbor on the class activity
- We will spend the first portion of today on the activity, then we will discuss as a class
- At the end of class, submit your work as an HTML file on Canvas (one per group, list all your names)
Iteration motivation
What are some potential issues with the following code?
purrr::map
What is the map function doing here?
purrr::map
map: apply a function to each element of a list or vector
- first argument: a list or vector
grade_files: a vector of CSV file names to read into R
- second argument: the function to apply
read_csv: function to read a CSV file into R
“For each file in grade_files, apply the read_csv function to read it into R”
purrr::map
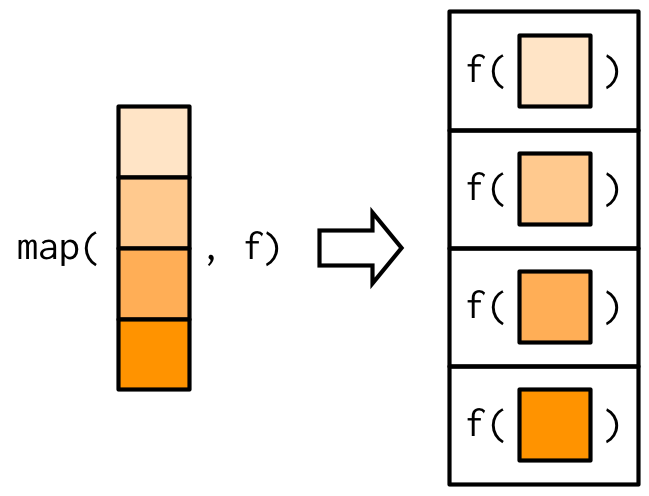
(Image from Advanced R (2nd edition), Chapter 9)
purrr::map
map: apply a function to each element of a list or vector
Output: a list
[1] "list"[1] 10Rows: 35
Columns: 14
$ student_id <dbl> 55817, 32099, 40295, 54195, 15297, 81786, 49747, 78226, 102…
$ hw_1 <dbl> 10, 10, 10, 10, 10, 7, 10, 10, 9, 9, 8, 10, 10, 7, 8, 8, 10…
$ hw_2 <dbl> 10, 9, 10, 9, 8, 8, 9, 9, 9, 8, 10, 10, 10, 6, 9, 10, 8, 10…
$ hw_3 <dbl> 9, 10, 9, 9, 9, 6, 8, 9, 10, 10, 8, 9, 9, 9, 10, 9, 10, 8, …
$ hw_4 <dbl> 9, 9, 9, 6, 10, 6, 8, 10, 7, 9, 9, 10, 10, 9, 9, 8, 9, 10, …
$ hw_5 <dbl> 10, 10, 10, 9, 10, NA, 8, 9, 10, 9, NA, 10, 10, 4, 8, 10, 9…
$ hw_6 <dbl> 10, 9, 9, 9, 9, 6, 8, 10, 9, 9, 10, 10, 10, 8, NA, 9, 10, 1…
$ hw_7 <dbl> 10, 10, 9, 9, 10, 5, 6, 10, 8, 10, 8, 10, 10, 5, 7, 9, 9, 9…
$ hw_8 <dbl> 9, 10, 10, 9, 9, 7, 9, 9, 9, 10, 10, 10, 10, 8, 10, 9, 10, …
$ hw_9 <dbl> 8, 10, 10, 8, 10, 7, 7, 10, 10, 10, 8, 9, 9, 9, 8, 9, 10, 1…
$ midterm_1 <dbl> 97, 90, 95, 95, 94, 70, 79, 95, 89, 96, 90, 97, 88, 68, 86,…
$ midterm_2 <dbl> 96, 93, 91, 96, 92, 73, 83, 95, 84, 97, 87, 98, 93, 81, 88,…
$ final_exam <dbl> 93, 93, 97, 91, 93, 77, 77, 97, 88, 94, 89, 96, 98, 76, 85,…
$ project <dbl> 93, 93, 97, 90, 87, 76, 84, 93, 89, 93, 82, 100, 93, 75, 89…purrr::map
map: apply a function to each element of a list or vector
Output: a list
Rows: 29
Columns: 10
$ student_id <dbl> 88275, 99752, 81485, 34888, 56497, 14363, 31087, 34334, 278…
$ hw_1 <dbl> 8, 8, 10, 4, 5, 7, 5, 10, 10, 7, 6, 7, 7, 9, 9, NA, NA, 7, …
$ hw_2 <dbl> 6, 10, 9, 5, 8, 7, 8, 9, 10, NA, 8, 10, 8, NA, 10, 10, 8, 6…
$ hw_3 <dbl> 8, 10, 9, 6, 7, 10, 6, 7, 10, 10, 5, 10, 8, 7, 9, 8, 7, 8, …
$ hw_4 <dbl> 10, 10, 9, 9, 7, 9, 4, 8, 10, 7, 7, 8, 9, 9, 9, 9, NA, 7, 1…
$ hw_5 <dbl> 6, 7, 9, 7, 7, 9, 8, 8, 9, 6, 6, 8, 6, NA, 10, 8, 6, 5, 9, …
$ midterm_1 <dbl> 88, 84, 86, 68, 66, 85, 73, 67, 93, 72, 52, 85, 71, 81, 96,…
$ midterm_2 <dbl> 83, 88, 88, 70, 79, 84, 73, 64, 94, 74, 59, 90, 63, 88, 96,…
$ final_exam <dbl> 80, 88, 93, 58, 68, 82, 77, 69, 95, 71, 56, 82, 74, 90, 93,…
$ project <dbl> 84, 87, 93, 61, 75, 81, 71, 73, 93, 65, 51, 87, 65, 89, 94,…Another example
What will this code produce?
Another example
map variants
If we want to return a vector instead of a list, we can use one of the map variants. E.g.:
Another example
What will this code produce?
Another example
Class activity
Error in `map()`:
ℹ In index: 1.
Caused by error in `summarize()`:
ℹ In argument: `slope = cov(, , use = "complete.obs")/var(, na.rm = T)`.
Caused by error in `cov()`:
! is.numeric(x) || is.logical(x) is not TRUEWhat is causing this error?
Class activity
[[1]]
# A tibble: 1 × 1
slope
<dbl>
1 0.756
[[2]]
# A tibble: 1 × 1
slope
<dbl>
1 0.871
[[3]]
# A tibble: 1 × 1
slope
<dbl>
1 1.07
[[4]]
# A tibble: 1 × 1
slope
<dbl>
1 0.873
[[5]]
# A tibble: 1 × 1
slope
<dbl>
1 0.859
[[6]]
# A tibble: 1 × 1
slope
<dbl>
1 0.881
[[7]]
# A tibble: 1 × 1
slope
<dbl>
1 0.963
[[8]]
# A tibble: 1 × 1
slope
<dbl>
1 0.969
[[9]]
# A tibble: 1 × 1
slope
<dbl>
1 1.01
[[10]]
# A tibble: 1 × 1
slope
<dbl>
1 0.983purrr::map
The function to be applied in map must take a single argument
Another example
What do you think will be the output of this code?
Another example
Another example
What do you think will be the output of this code?
Another example
How do we ignore the NA when calculating the mean?
Another example
Will this code work?
Another example
Error in mean.default(na.rm = T): argument "x" is missing, with no defaultProblem: mean(na.rm=T) is not a function! It is a call to the mean function.
Solution: use an anonymous function!