# A tibble: 260 × 38
country `1975` `1976` `1977` `1978` `1979` `1980` `1981` `1982` `1983` `1984`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghan… NA NA NA NA 4.99 NA NA NA NA NA
2 Albania NA NA NA NA NA NA NA NA NA NA
3 Algeria NA NA NA NA NA NA NA NA NA NA
4 Andorra NA NA NA NA NA NA NA NA NA NA
5 Angola NA NA NA NA NA NA NA NA NA NA
6 Anguil… NA NA NA NA NA NA NA NA NA 95.7
7 Antigu… NA NA NA NA NA NA NA NA NA NA
8 Argent… NA NA NA NA NA 93.6 NA NA NA NA
9 Armenia NA NA NA NA NA NA NA NA NA NA
10 Aruba NA NA NA NA NA NA NA NA NA NA
# ℹ 250 more rows
# ℹ 27 more variables: `1985` <dbl>, `1986` <dbl>, `1987` <dbl>, `1988` <dbl>,
# `1989` <dbl>, `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>,
# `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>,
# `1999` <dbl>, `2000` <dbl>, `2001` <dbl>, `2002` <dbl>, `2003` <dbl>,
# `2004` <dbl>, `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>Reshaping data
Warmup activity
Work on the activity (handout) with a neighbor, then we will discuss as a class
Warmup
Question: What does a row in this data represent?
Warmup
# A tibble: 260 × 38
country `1975` `1976` `1977` `1978` `1979` `1980` `1981` `1982` `1983` `1984`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghan… NA NA NA NA 4.99 NA NA NA NA NA
2 Albania NA NA NA NA NA NA NA NA NA NA
3 Algeria NA NA NA NA NA NA NA NA NA NA
4 Andorra NA NA NA NA NA NA NA NA NA NA
5 Angola NA NA NA NA NA NA NA NA NA NA
6 Anguil… NA NA NA NA NA NA NA NA NA 95.7
7 Antigu… NA NA NA NA NA NA NA NA NA NA
8 Argent… NA NA NA NA NA 93.6 NA NA NA NA
9 Armenia NA NA NA NA NA NA NA NA NA NA
10 Aruba NA NA NA NA NA NA NA NA NA NA
# ℹ 250 more rows
# ℹ 27 more variables: `1985` <dbl>, `1986` <dbl>, `1987` <dbl>, `1988` <dbl>,
# `1989` <dbl>, `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>,
# `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>,
# `1999` <dbl>, `2000` <dbl>, `2001` <dbl>, `2002` <dbl>, `2003` <dbl>,
# `2004` <dbl>, `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>Question: What does a row in this data represent?
Each row is one country
Warmup
# A tibble: 260 × 38
country `1975` `1976` `1977` `1978` `1979` `1980` `1981` `1982` `1983` `1984`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghan… NA NA NA NA 4.99 NA NA NA NA NA
2 Albania NA NA NA NA NA NA NA NA NA NA
3 Algeria NA NA NA NA NA NA NA NA NA NA
4 Andorra NA NA NA NA NA NA NA NA NA NA
5 Angola NA NA NA NA NA NA NA NA NA NA
6 Anguil… NA NA NA NA NA NA NA NA NA 95.7
7 Antigu… NA NA NA NA NA NA NA NA NA NA
8 Argent… NA NA NA NA NA 93.6 NA NA NA NA
9 Armenia NA NA NA NA NA NA NA NA NA NA
10 Aruba NA NA NA NA NA NA NA NA NA NA
# ℹ 250 more rows
# ℹ 27 more variables: `1985` <dbl>, `1986` <dbl>, `1987` <dbl>, `1988` <dbl>,
# `1989` <dbl>, `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>,
# `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>,
# `1999` <dbl>, `2000` <dbl>, `2001` <dbl>, `2002` <dbl>, `2003` <dbl>,
# `2004` <dbl>, `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>Question: Is this table in “wide” or “narrow” format?
Warmup
# A tibble: 260 × 38
country `1975` `1976` `1977` `1978` `1979` `1980` `1981` `1982` `1983` `1984`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghan… NA NA NA NA 4.99 NA NA NA NA NA
2 Albania NA NA NA NA NA NA NA NA NA NA
3 Algeria NA NA NA NA NA NA NA NA NA NA
4 Andorra NA NA NA NA NA NA NA NA NA NA
5 Angola NA NA NA NA NA NA NA NA NA NA
6 Anguil… NA NA NA NA NA NA NA NA NA 95.7
7 Antigu… NA NA NA NA NA NA NA NA NA NA
8 Argent… NA NA NA NA NA 93.6 NA NA NA NA
9 Armenia NA NA NA NA NA NA NA NA NA NA
10 Aruba NA NA NA NA NA NA NA NA NA NA
# ℹ 250 more rows
# ℹ 27 more variables: `1985` <dbl>, `1986` <dbl>, `1987` <dbl>, `1988` <dbl>,
# `1989` <dbl>, `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>,
# `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>,
# `1999` <dbl>, `2000` <dbl>, `2001` <dbl>, `2002` <dbl>, `2003` <dbl>,
# `2004` <dbl>, `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>Question: Is this table in “wide” or “narrow” format?
Wide format – there is a column for each value of a variable (year)
Warmup
# A tibble: 260 × 38
country `1975` `1976` `1977` `1978` `1979` `1980` `1981` `1982` `1983` `1984`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghan… NA NA NA NA 4.99 NA NA NA NA NA
2 Albania NA NA NA NA NA NA NA NA NA NA
3 Algeria NA NA NA NA NA NA NA NA NA NA
4 Andorra NA NA NA NA NA NA NA NA NA NA
5 Angola NA NA NA NA NA NA NA NA NA NA
6 Anguil… NA NA NA NA NA NA NA NA NA 95.7
7 Antigu… NA NA NA NA NA NA NA NA NA NA
8 Argent… NA NA NA NA NA 93.6 NA NA NA NA
9 Armenia NA NA NA NA NA NA NA NA NA NA
10 Aruba NA NA NA NA NA NA NA NA NA NA
# ℹ 250 more rows
# ℹ 27 more variables: `1985` <dbl>, `1986` <dbl>, `1987` <dbl>, `1988` <dbl>,
# `1989` <dbl>, `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>,
# `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>,
# `1999` <dbl>, `2000` <dbl>, `2001` <dbl>, `2002` <dbl>, `2003` <dbl>,
# `2004` <dbl>, `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>Question: What would the data look like in narrow form?
Warmup
Literacy data in narrow form:
# A tibble: 571 × 3
country year literacy_rate
<chr> <chr> <dbl>
1 Afghanistan 1979 4.99
2 Afghanistan 2011 13
3 Albania 2001 98.3
4 Albania 2008 94.7
5 Albania 2011 95.7
6 Algeria 1987 35.8
7 Algeria 2002 60.1
8 Algeria 2006 63.9
9 Angola 2001 54.2
10 Angola 2011 58.6
# ℹ 561 more rowsAnother example
Data on three patients (A, B, C), with two blood pressure measurements (bp1 and bp2) per patient:
id bp1 bp2
1 A 100 120
2 B 140 115
3 C 120 125How might we want to reshape this data?
Another example
Original data:
id bp1 bp2
1 A 100 120
2 B 140 115
3 C 120 125Reshaped data:
id measurement value
1 A bp1 100
2 A bp2 120
3 B bp1 140
4 B bp2 115
5 C bp1 120
6 C bp2 125Question: how do we do this reshaping in R?
Reshaping data: pivot_longer
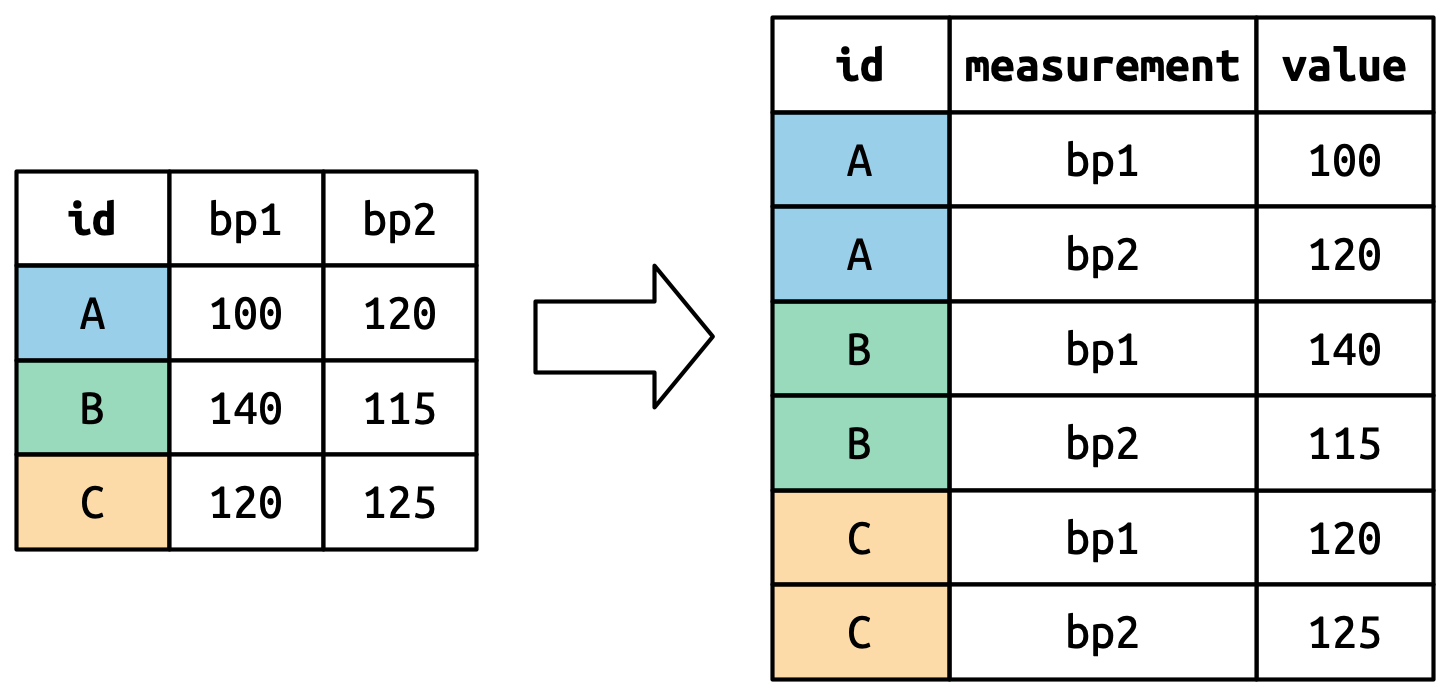
(Image and example from R for Data Science)
pivot_longer
# A tibble: 260 × 38
country `1975` `1976` `1977` `1978` `1979` `1980` `1981` `1982` `1983` `1984`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghan… NA NA NA NA 4.99 NA NA NA NA NA
2 Albania NA NA NA NA NA NA NA NA NA NA
3 Algeria NA NA NA NA NA NA NA NA NA NA
4 Andorra NA NA NA NA NA NA NA NA NA NA
5 Angola NA NA NA NA NA NA NA NA NA NA
6 Anguil… NA NA NA NA NA NA NA NA NA 95.7
7 Antigu… NA NA NA NA NA NA NA NA NA NA
8 Argent… NA NA NA NA NA 93.6 NA NA NA NA
9 Armenia NA NA NA NA NA NA NA NA NA NA
10 Aruba NA NA NA NA NA NA NA NA NA NA
# ℹ 250 more rows
# ℹ 27 more variables: `1985` <dbl>, `1986` <dbl>, `1987` <dbl>, `1988` <dbl>,
# `1989` <dbl>, `1990` <dbl>, `1991` <dbl>, `1992` <dbl>, `1993` <dbl>,
# `1994` <dbl>, `1995` <dbl>, `1996` <dbl>, `1997` <dbl>, `1998` <dbl>,
# `1999` <dbl>, `2000` <dbl>, `2001` <dbl>, `2002` <dbl>, `2003` <dbl>,
# `2004` <dbl>, `2005` <dbl>, `2006` <dbl>, `2007` <dbl>, `2008` <dbl>,
# `2009` <dbl>, `2010` <dbl>, `2011` <dbl>pivot_longer
# A tibble: 9,620 × 3
country year literacy_rate
<chr> <chr> <dbl>
1 Afghanistan 1975 NA
2 Afghanistan 1976 NA
3 Afghanistan 1977 NA
4 Afghanistan 1978 NA
5 Afghanistan 1979 4.99
6 Afghanistan 1980 NA
7 Afghanistan 1981 NA
8 Afghanistan 1982 NA
9 Afghanistan 1983 NA
10 Afghanistan 1984 NA
# ℹ 9,610 more rowspivot_longer
litF |>
pivot_longer(
cols = -country,
names_to = "year",
values_to = "literacy_rate"
) |>
drop_na()# A tibble: 571 × 3
country year literacy_rate
<chr> <chr> <dbl>
1 Afghanistan 1979 4.99
2 Afghanistan 2011 13
3 Albania 2001 98.3
4 Albania 2008 94.7
5 Albania 2011 95.7
6 Algeria 1987 35.8
7 Algeria 2002 60.1
8 Algeria 2006 63.9
9 Angola 2001 54.2
10 Angola 2011 58.6
# ℹ 561 more rowspivot_longer
litF |>
pivot_longer(
cols = -country,
names_to = "year",
values_to = "literacy_rate",
values_drop_na = T
)# A tibble: 571 × 3
country year literacy_rate
<chr> <chr> <dbl>
1 Afghanistan 1979 4.99
2 Afghanistan 2011 13
3 Albania 2001 98.3
4 Albania 2008 94.7
5 Albania 2011 95.7
6 Algeria 1987 35.8
7 Algeria 2002 60.1
8 Algeria 2006 63.9
9 Angola 2001 54.2
10 Angola 2011 58.6
# ℹ 561 more rowsExample 2
Now consider the following table:
What will the following code return?
Example 2
Example 2
Reshaped data:
Example 3
Consider the following example data:
id bp_1 bp_2 hr_1 hr_2
1 1 100 120 60 77
2 2 120 115 75 81
3 3 125 130 80 93What if we want the data to look like this:
# A tibble: 12 × 4
id measurement stage value
<dbl> <chr> <chr> <dbl>
1 1 bp 1 100
2 1 bp 2 120
3 1 hr 1 60
4 1 hr 2 77
5 2 bp 1 120
6 2 bp 2 115
7 2 hr 1 75
8 2 hr 2 81
9 3 bp 1 125
10 3 bp 2 130
11 3 hr 1 80
12 3 hr 2 93Example 3
id bp_1 bp_2 hr_1 hr_2
1 1 100 120 60 77
2 2 120 115 75 81
3 3 125 130 80 93df_3 |>
pivot_longer(cols = -id,
names_to = c("measurement", "stage"),
names_sep = "_",
values_to = "value")# A tibble: 12 × 4
id measurement stage value
<dbl> <chr> <chr> <dbl>
1 1 bp 1 100
2 1 bp 2 120
3 1 hr 1 60
4 1 hr 2 77
5 2 bp 1 120
6 2 bp 2 115
7 2 hr 1 75
8 2 hr 2 81
9 3 bp 1 125
10 3 bp 2 130
11 3 hr 1 80
12 3 hr 2 93Example 3
Step 1: Pivot
# A tibble: 6 × 3
id measurement value
<dbl> <chr> <dbl>
1 1 bp_1 100
2 1 bp_2 120
3 1 hr_1 60
4 1 hr_2 77
5 2 bp_1 120
6 2 bp_2 115Step 2: Separate columns
# A tibble: 6 × 4
id measurement stage value
<dbl> <chr> <chr> <dbl>
1 1 bp 1 100
2 1 bp 2 120
3 1 hr 1 60
4 1 hr 2 77
5 2 bp 1 120
6 2 bp 2 115Class activity
https://sta279-f25.github.io/class_activities/ca_04.html
- Work with a neighbor on the class activity
- At the end of class, submit your work as an HTML file on Canvas (one per group, list all your names)
For next time, read:
- Chapter 5 in R for Data Science (2nd ed.)